Before reading this post, see the introductory post for this series: Particles and Waves.
Among our goals is the desire to understand the duality of data and code. This duo represents one of the most fundamental pairs of particles and waves in software. However, careful selection of a bounded context can reveal particles and waves at any level. Combined with the observation that particles and space are generally easier to recognize and reason about than waves and time, let’s zoom in on data before tackling code.
Data Structures
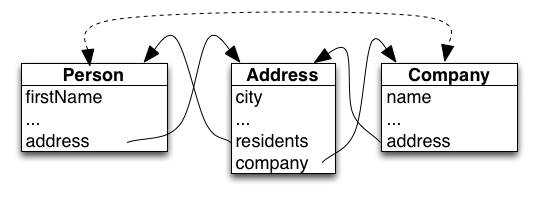
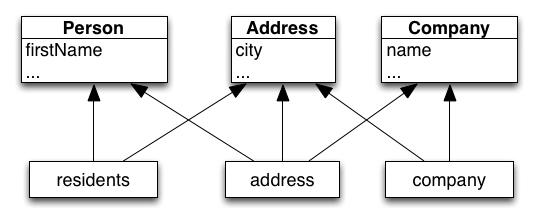
Perhaps surprisingly, there is only a small number of foundational abstract data types. Wikipedia lists some common examples: List, Set, Multiset (Bag), Map, Graph, Stack, Queue, Priority Queue, etc. If you squint just right, there are really only two fundamental types of data containers: lists and bags. Every simple data structure can be classified as ordered or unordered. Common modes of use, such as FILO stacks and FIFO queues, are really just specializations of more generalized lists. Similar for maps and graphs; these are specialized bags. More complex data structures can be recognized as a careful composite of ordered and unordered substructures. Even the ubiquitous map can be viewed as a bag of lists, where each list is a key/value pair, constraining keys to be unique.
Individual data structures are the traditional particles we think of when we think about the data in our code. From a typical vantage point, the context that bounds these particles is so far away that we generally don’t ever perceive it. It’s only when we take a step back from a fragment of code and look at a complete system that we can perceive a common and relevant bounded context: a “database”.
Databases
Numbers, such as 5, or strings, such as "foo", have sufficient structure to
be recognized in our shared global context made up of decimal numbers and
unicode. However, 5 is useless on its own. We need to know how to interpret
it. For that, we need more shared context. Let’s introduce a database with a
fruit table and say that our favorite number is a fruit ID. Now we can lookup
up the fruit ID and find out that we’re talking about bananas. It turns out
that our number particle is just one of many particles in a banana wave
traveling through our database medium.
By changing our perspective, we can study other bounded contexts, revealing more waves. When this happens, there tends to be an inversion: ordered becomes unordered and vice versa. Additional inversions are explored in sections below. For now, let’s choose the perspective of a programming language runtime implementer. From this vantage point, the heap is a database. A simple ordered data structure such as a pair, is actually represented with pointers, no different than our banana ID. The pair structure arrises from the interplay between a ordered structure with two pointers and an unordered structure, a map, encoded as memory itself, that translates addresses to objects. Shift your perspective again, from application user-space to operating system kernel-space and the question of whether memory is ordered or unordered depends on your perspective on virtual memory.
One common form of data warrants a special note: graphs. The easiest representation of a graph in a traditional programming language is to utilize memory pointers. However, this representation is impoverished. It forcibly equates nodes with their graphs that they are part of and sets an implicit boundary equal to all of memory. As much as possible, graphs and nodes should be clearly delimited. A graph should rightfully be considered as a database of nodes.
Openness
For the sake of concision, I will refer to data built up from other data in the implicit “global” context as “structural data”, or simply “structures”. Similarly, data derived from the relationship between structures and an explicit context will be referred to as “relational data”, or simply “relations”. These shorthands are not to be confused with the more specific concepts of C-style “structures” or traditional relational database “relations”, despite my abuse of the intentional analogies.
A key distinction and advantage of relational data is its inherit openness. One fruit ID may appear in many tables. Adding a new table to a database extends the meaning of that fruit ID without impacting any existing relations. We can also extend the meaning of that one fruit ID by moving the context boundary: switch databases, connect to a second database, talk to an external fruit service, etc. By contrast, structural data is closed. Structural data can only be “extend” by replacing it with a slightly varied structure; appending an element to a four element list produces a new list of five elements.
Time is the most important dimension of openness. Growth occurs over time as we
add tables to a database, mmap additional pages in to virtual memory, or
simply add keys to a map. The impact of time on the interpretation of data is a
massive topic, to be discussed at another — ahem — time.
Cutting Along The Grain
Much pain in software designs stems from a conflict between the programmer’s intuition and the nature of the data they are working with. Each kind of data “wants” to be used in a particular way. Given the ability to recognize structures and relations, we can choose the most appropriate end of this duality spectrum; then choose strategies for working with such data according to its wants.
Here’s a summary of each kind of data’s respective usual wants:
| Structures | Relations | |
|---|---|---|
| Order | Ordered | Unordered |
| Substructure | Positional | Associative |
| Mutability | Immutable | Mutable |
| Hierarchy | Contain Children | Point To Parents |
| Construction | Bottom-Up | Top-Down |
| Cycles | Acyclic | Cyclic |
| Limits | Finite | Infinite |
Each of these wants can be overridden by moving the bounds of your context. Stuff tuples in to the context of a table to exploit associativity; or scope the context of a database to a transaction to build relations out of temporary ids, bottom-up.
Again, time is too vast a topic to discuss in detail here. Suffice to say, time can be bounded by “stopping” it and/or by choosing a time slice. Stopped time turns the mutable in to immutable and a time slice can turn the infinite in to the finite. Conversely, stopped or sliced time can be started and opened again: stick an immutable structure in a mutable box or connect a live pipe to a queue.
Perspective
This perspective has dramatically hastened and improved how I design software. Carefully considering bounded contexts strongly guides many design choices. In situations where I used to find myself flip-flopping on some tradeoff, I now find myself happily choosing and committing to an appropriate blend of structural and relational data. Future posts in this series will revisit this tradeoff through some more concrete examples.

{kind=link}